RISC-V 乘法延伸如何將高效的 32 位元乘法新增至 RV32I
RISC-V 指令集架構 (ISA) 是在 2010 年由美國加州柏克萊大學所創。雖然 RISC 是指精簡指令集電腦/核心,但製造商在採用 RISC ISA 時,卻忍不住在這裡新增一條指令,在哪裡新增一種定址模式,填入運算碼對應,直到架構更像是 CISC,而不是 RISC。不過,柏克萊的 RISC-V 開發人員對於讓他們的核心維持純正 RISC 抱持非常嚴謹的態度。RV32I RISC-V ISA 的設計僅採用 47 個基本指令 (這個數字對於《星艦迷航記》傳統粉絲而言別具意義),而過了 11 年後,此數字依然沒變。
在維持少量基本指令的背後,原本理念是複雜 CISC 指令可重現為一系列的簡易 RISC 指令。就我的經驗而言,此做法能否增強編碼效能和減少程式碼大小,係取決於應用。過去這樣做確實有效。甚至於 Arm 也在運算碼對應中新增了複雜指令。
雖然額外指令能夠幫助增進效能,但若採用具 32 位元指令的 32 位元核心,而您又希望能夠將一些 32 位元指令壓縮至 16 位元指令以節省空間,此時情況就會變得更為複雜。不過,若要新增 16 位元指令,核心必須在運算碼對應中具有額外空間,以供容納這些壓縮的指令,並且新增 CISC 指令可減少可用運算碼的數量。
此為 RISC-V 真正大放光彩的優勢所在。Arm 後來新增了 Thumb2 壓縮指令格式,並藉由新增獨立的 16 位元 ISA,將這些 16 位元指令納入現有的 ISA 中。不過,RISC-V ISA 一開始在設計上即提供壓縮指令選項,因此僅有一個 ISA。這樣可讓核心維持簡易和高效率,也可精簡半導體設計與測試工作。
運用乘法指令增強 RISC-V RV32I ISA
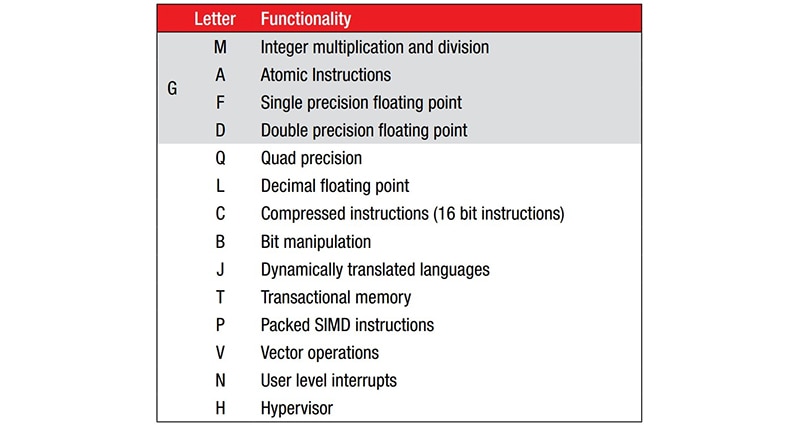
製造商可藉由新增標準化指令延伸來擴展 47 指令 ISA (圖 1)。由於基本 ISA 無乘法或除法指令,因此 M 延伸提供該項功能。例如,系統會為具有 M 延伸的 RV32I 指定 RV32IM。
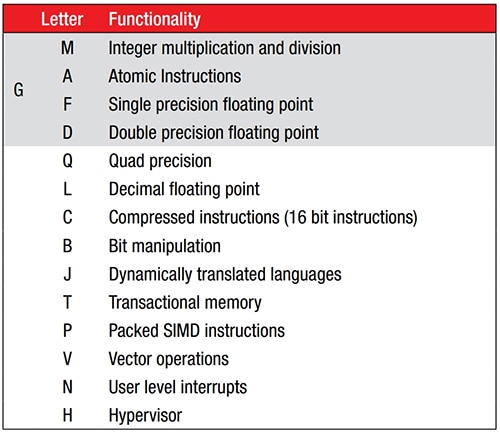 圖 1:47 指令的 RISC-V 基本 ISA 可藉由新增標準化指令延伸進行擴展,並在核心名稱後面以字母尾碼表示。(圖片來源:RISC-V.org)
圖 1:47 指令的 RISC-V 基本 ISA 可藉由新增標準化指令延伸進行擴展,並在核心名稱後面以字母尾碼表示。(圖片來源:RISC-V.org)
SparkFun Electronics 的 RED-V Thing Plus 即是具有 M 延伸的核心範例,其採用開放原始碼的 150 MHz Freedom E310 (FE310) 32 位元 RISC-V 微控制器。FE310 核心指定為 RV32IMAC。請參考圖 1,除了基本整數數學 (I) 能力外,還支援整數乘法 (M)、原子指令 (A) 和壓縮指令 (C)。
SparkFun 的 DEV-15799 RED-V (讀做「red five」) 是一款 RISC-V 評估板 (圖 2),配備 32 MB 的程式記憶體 QSPI 快閃記憶體,且配備可介接主機電腦的 USB-C 連接器,以執行供電、編程和除錯。此外,還有一個可用來提供電池電力的額外連接器。
 圖 2:SparkFun 的 DEV-15799 評估板用於評估開放原始碼的 150 MHz FE310 RV32IMAC RISC-V 核心。其可透過 USB-C 介面介接至主機電腦。(圖片來源:SparkFun Electronics)
圖 2:SparkFun 的 DEV-15799 評估板用於評估開放原始碼的 150 MHz FE310 RV32IMAC RISC-V 核心。其可透過 USB-C 介面介接至主機電腦。(圖片來源:SparkFun Electronics)
M 延伸可新增有符號和無符號 32/32 除法指令 DIV 和 DIVU,以及有符號和無符號餘數指令 REM 和 REMU。此外,還新增四個乘法指令:
- MUL 執行 32 x 32 暫存器乘法,並在暫存器中儲存 64 位元結果的低 32 位元。
- MULH 和 MULHU 分別執行有符號和無符號暫存器乘法,並在暫存器中儲存 64 位元結果的高 32 位元。
- MULSHU 執行有符號 x 無符號暫存器乘法,並在暫存器中儲存 64 位元結果的高 32 位元。
因此,針對 32 x 32 = 64 的無符號乘法,建議的程式碼序列為:
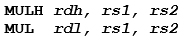
其中,暫存器 rs1 和 rs2 分別為被乘數與乘數,暫存器 rdh 和 rdl 則分別為高低 32 位元結果。
ISA 會將 64 位元乘法結果分為兩個 32 位元運算,因此無須新增複雜的 32 x 32 = 64 CISC 指令。這符合採用簡易指令執行 CISC 運算的 RISC 理念。
基本 RV32I ISA 中的大部分指令皆僅在一個指令時脈週期中執行,而 RED-V FE310 中的這些乘法指令則需要五個指令時脈週期。因此,以上建議的程式碼序列採用十個時脈週期。雖然這在 150 MHz 時可以接受,但對於極低功率、低時脈速度微控制器應用而言中斷至關緊要,而 5 MHz 時十個週期乘法的等候時間太久,無法滿足關鍵中斷需求。針對這些情況,韌體開發人員會使用允許中斷的複雜組合語言子常式來執行乘法。
不過,FE310 核心可運用連續指令,並透過巨集運算融合在內部將這些指令融合為一個更快的指令。核心微架構可將兩個指令融合為一個內部指令,其執行速度快於十個週期。RISC-V 微架構會針對一些程式碼序列自動執行此工作,例如 indexed loads、load-pair 和 store-pair 指令,可大幅提升執行速度。更棒的是,由於 FE310 支援「C」延伸,且可融合兩個相容的 16 位元壓縮指令,因此兼具程式碼與執行速度兩種優勢。
Arm 在後期於架構中新增巨集運算融合 (如同壓縮指令),但 RISC-V 起初在設計上即支援巨集運算融合。要真正瞭解程式碼壓縮的優勢以及巨集運算融合的啟動時機,最佳方式是觀察其在 SparkFun DEV-15799 等評估板上的運作行為。您可在除錯器中檢查程式碼,瞭解 FE310 微架構如何擷取和執行每個指令。這可讓您更深入瞭解組合語言的運作行為,有助於運用支援程式碼壓縮和巨集運算融合的 C 編譯器來撰寫高效的程式碼。
結論
RISC-V ISA 深感自豪地向各界宣告,其為僅具有 47 個基本指令的真正精簡指令集。這可透過諸如「M」乘法延伸等標準化延伸進行增強,此類延伸能新增乘法和除法指令。RISC-V 架構內建巨集運算融合,可加快諸如連續乘法指令等相容指令的程式碼執行速度,而「C」壓縮延伸可減少程式碼大小。運用壓縮指令結合巨集運算融合,讓您擁有勝過其他架構的顯著效能優勢。
關於作者

Bill Giovino 是電子工程師,擁有美國雪城大學的電機工程學士學位,也是少數從設計工程師跨足現場應用工程師,再到技術行銷領域的成功典範之一。
Bill 過去 25 年來熱衷於向科技和非科技業的對象推廣新技術,包括 STMicroelectronics、Intel 和 Maxim Integrated 等多家企業。Bill 在 STMicroelectronics 任職期間,曾協助領導該公司順利進軍微控制器領域。在 Infineon 任職時,則策劃出該公司首款在美國汽車業大受歡迎的微控制器設計。Bill 目前是他個人公司 CPU Technologies 的行銷顧問,曾協助諸多企業讓表現不佳的產品重獲市場青睞。
Bill 更是採用物聯網的先驅,包括在微控制器中首次納入完整的 TCP/IP 堆疊。Bill 致力於推廣「用教育促成銷售」的理念,也認可在線上推銷產品時有清楚完整文字說明的重要性。他在 LikedIn 熱門的半導體銷售和行銷群組中擔任管理員,也擁有深厚的 B2E 知識。

Have questions or comments? Continue the conversation on TechForum, Digi-Key's online community and technical resource.
Visit TechForum
此作者的其他文章