

目錄表
置頂
邊緣運算
熱門邊緣運算內容
邊緣人工智慧與機器學習
機器學習訓練方法
嵌入式機器學習
熱門邊緣人工智慧內容
機器學習軟體 (包括 TensorFlow 和 LiteRT)
TensorFlow
LiteRT
PyTorch 和 ExecuTorch
熱門機器學習軟體內容
邊緣人工智慧和機器學習硬體
需求
NPU
TPU
入門級產品
中階產品
高階產品
專業級產品
更多產品
熱門邊緣人工智慧硬體內容
Edge Impulse
熱門 Edge Impulse 內容
熱門的 Edge Impulse 裝置
利用人工智慧進行感測
具有機器學習功能的視覺感測器
熱門的人工智慧視覺感測器
熱門人工智慧視覺感測器內容
具有機器學習功能的動作感測器
熱門的人工智慧動作感測器
熱門動作感測器內容
具有機器學習功能的環境感測器
熱門環境人工智慧感測器
邊緣人工智慧
邊緣運算顧名思義,即是在資料來源附近而非在雲端 (資料中心) 。智慧家庭助理 (Alexa 或 Siri) 等工具內建邊緣人工智慧。當您說「Hey Alexa」時,邊緣人工智慧就會識別該短語並喚醒智慧家庭助理。
邊緣人工智慧和機器學習改變系統和裝置處理資料的方式,讓使用者能夠在源頭進行即時決策,而不用依賴遠端伺服器。工程師順應技術快速發展的潮流,理解和應用這些概念對於開發智慧、自主系統非常重要,以便在各產業進行即時決策。本雜誌將介紹邊緣人工智慧和機器學習的硬體、軟體,以及一些應用,並說明這些技術可解決的問題。

邊緣運算
對運算服務的需求與日俱增,因此脫離大規模集中式資料中心的趨勢可能令人意外。不過,在資料來源附近進行運算可以減少隱私外洩的擔憂。網路邊緣,以前是指週邊裝置和終端機的領域,現在泛稱具有進階處理能力的地方。
許多即時作業推動了對邊緣運算的需求,這些應用可能已在我們身邊。
- 智慧家庭助理 (如 Alexa、Google 和 Siri) 使用「喚醒詞」偵測功能作為邊緣運算的一種形式。此情況必須採用邊緣運算,因為裝置必須迅速回應並維護使用者的隱私。
- 先進駕駛輔助系統 (ADAS) 的重要功能包括在駕駛偏離車道時發出提醒,因此不能等待資料來回雲端,也無法承擔網路回應延遲的風險。
- 病患監測 (如血糖監測儀) 需在患者附近運作, 只能將資料傳送到患者的智慧型手機 (或本機裝置),才能為需受保護的健康資料降低暴露到網際網路的任何可能。
- 預測性維護模型可對工業馬達的振動量進行異常偵測,藉此偵測馬達故障的時機。可能會觸發警報 (並在偵測到異常後傳送到雲端),但在其餘時間,軟體會在邊緣分析資料,進而減少網路擁塞。
邊緣運算和雲端運算如何區別? 解答
雲端運算通常是指位於資料中心的一套服務,通常在遠離資料的來源處進行處理。雲端運算工作負載會在伺服器上執行,伺服器會搭載中央處理器 (CPU) 或圖形處理器 (GPU)。
邊緣運算是指貼近資料來源的運算服務。邊緣運算工作負載通常會在微控制器或單板電腦 (SBC) 上處理。
熱門邊緣運算內容


使用 Efinix 的 Quantum 架構 FPGA,實作低功率、高效能的邊緣運算
使用 Efinix 的 Quantum 架構 FPGA,在 AI、ML 和影像處理的邊緣運算實作中達到更高的功率-效能-面積。

邊緣人工智慧與機器學習
從最廣泛的定義來看,人工智慧 (AI) 和機器學習 (ML) 就是利用電腦演算法和統計模型,無需接受直接明確的指令,就可提升任務表現。傳統程式設計需要明確的定義每個動作,但有了這些新技術,開發人員就不再需要提供所有定義,產品可自行提升效能和適應性,因此幾乎能運用在各種應用中,從網際網路內容推薦、語音辨識,到醫療科學和自動駕駛車等。
日常生活中有更多系統現在都包含一些機器學習互動,工程師和開發人員需瞭解這個領域,方能邁入使用者互動的未來。
人工智慧 (AI) 是一門龐大的學問,尤其是機器學習 (ML),更是邊緣最具潛力的領域。機器學習是依據統計演算法進行模式匹配的流程。
在機器學習中,常會使用神經網路進行訓練。下圖指出此類模型中的節點和權重。
 來源:
來源:深度學習是機器學習的一種特殊類型,擁有數個隱藏層於神經網路中。
 來源:
來源:什麼是機器學習模型? 解答
機器學習模型是一套經過設定的軟體程式,可依據在訓練資料中找到的模式,對輸入資料進行辨識與分類。透過訓練資料,機器學習模型可以擷取資料中發現的模式,然後利用這些模式預測未來的結果並微調出更精準的模型。
機器學習訓練方法
要獲得有效的機器學習模型,需要經過訓練。有幾種不同的學習方法可用於訓練模型。
- 監督式:這種訓練是以標示標籤與標記的樣本資料為基礎,已知其輸出值,用以檢查其正確性,就像由從旁指導一樣。這種類型的訓練通常用於分類工作或資料迴歸等應用。監督式訓練相當有用且非常準確,但其效果大部分取決於標記的資料集,且有可能無法處理新的輸入資料。
- 非監督式:非監督式訓練不使用具有明確輸出的已標籤訓練資料,而是利用學習演算法在未經標籤的資料集裡,對資料叢集進行研究、分析、尋找。通常,非監督式訓練會用於需要研究大型資料集,並找出資料點之間關係的應用。
- 半監督式 - 監督式和非監督式訓練的混合。訓練資料集含有已標記和未標籤的資料。雖然半監督式訓練可處理的輸入資料比其他訓練方法更多元,但比起監督式或非監督式訓練來說更加複雜,而且未經標籤的資料品質可能會影響最終模型的準確性。
- 基於人類回饋的強化學習 (RLHF):這種訓練類型需要使用可明確定義的動作,還要搭配效能指標,以及可評分和改善的結果。定義規則集和可以採取的行動後,強化訓練就可不斷反覆迭代,以評估不同的行動方針,達成目標條件。
嵌入式機器學習
嵌入式機器學習屬於機器學習的一個子集,專注於執行以下條件的模型:
- 低延遲 (無需等待伺服器或處理網路連結到伺服器的延遲)
- 低頻寬 (不透過網路回傳高解析度資料)
- 低功耗 (僅消耗 mW 而非 W)
嵌入式機器學習模型無須仰賴大型資料處理硬體 (如伺服器或個人電腦),就可部署到小型低功率裝置 (如微控制器、FPGA、DSP)。
為嵌入式機器學習應用訓練模型,可在伺服器或電腦上執行。在此過程中,將所有資料輸入,便可產生模型。
嵌入式機器學習模型產生後,就可在嵌入式系統中執行。嵌入式機器學習中的常見應用包括對喚醒詞的識別和啟動、人員或物體的辨識,以及依據感測器的資料流發現異常。
邊緣人工智慧 (或嵌入式機器學習) 有什麼優點?解答
- 低延遲:無需等待遠端伺服器或網路延遲
- 低數據頻寬:不會透過網路傳送或回傳大量高解析度資料
- 隱私:利用預先篩選的感測器輸出,在邊緣設備上進行決策,資料不需透過網際網路傳播
- 低功耗:嵌入式機器學習消耗的電力僅有數毫瓦,而非幾瓦,因此非常適合電池供電的行動裝置
- 資料佔用空間小:嵌入式機器學習預期安裝在小容量的快閃記憶體中,大約只需幾十 KB
- 經濟且低成本的裝置:嵌入式機器學習可以在 32 位元 MCU 上以本機模式執行,整個系統通常不到 50 美元
熱門邊緣人工智慧內容


如何使用熟悉的工具在 FPGA 部署邊緣 AI
瞭解 Altera Agilex 5 與 Agilex 3 FPGA 搭載 AI 張量區塊,如何解決邊緣 AI 的難題,以及如何用 FPGA AI Suite 加速開發。


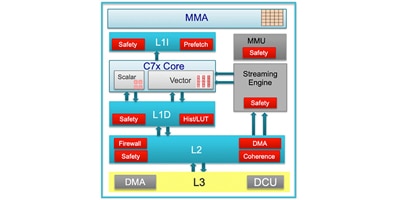
TI Edge AI - AM6xA 處理器與深度學習加速器及其效率
TI 處理器與深度學習加速器 TI 的 AM6xA(如 AM68Ax 和 AM69Ax)Edge AI 處理器採用異質架構,具有用於深度學習運算的專用加速器。
機器學習軟體 (包括 TensorFlow 和 LiteRT)
TensorFlow
TensorFlow 是一個免費的開源軟體庫,可用來構建、訓練、部署機器學習模型。最初由 Google 於 2011 年針對 Google Brain 專案而開發,之後在 2015 年向公眾開放,並於 2019 年發佈更新和當前版本 TensorFlow 2.0。
TensorFlow 是機器學習訓練以及深度神經網路推論領域最熱門且最廣泛使用的框架。許多開發人員會透過 Python API 函式庫與 TensorFlow 進行互動,但 TensorFlow 也可相容於 Java、JavaScript 和 C++ 程式語言。更有第三方套裝可增加選項,因此可使用 MATLAB、R、Haskell、Rust 等幾乎各種語言。
LiteRT
LiteRT (原 TensorFlow Lite) 是 TensorFlow 的一個子集,專為小規模工作所設計。包括硬體和功率受限的裝置,例如嵌入式系統、行動裝置、邊緣運算裝置。開發人員可以使用 TensorFlow 訓練、建立或修改現有的機器學習模型,然後使用 LiteRT 將其轉換為更小、更有效率的軟體套裝,就可以在行動裝置上作業。
 資料來源:
資料來源:然而,機器學習模型在部署到微控制器平台後,通常就不會在裝置上進一步訓練,因為在本機上訓練需要耗費大量運算能力與時間。這表示模型通常已經完全經過離線式訓練,沒有新的資料來源。這種受限的做法正好非常適合只要執行單一任務的應用,但需要對大量資料進行分類。
TensorFlow 和 LiteRT 有什麼不同? 解答
TensorFlow 需要更大的運算硬體,並且要搭配完整的一般用途作業系統 (GPOS)。
LiteRT 經過最佳化,可在嵌入式系統、行動裝置、邊緣運算裝置上執行機器學習模型。
Raspberry Pi 4 等執行 GPOS 的單板電腦 (SBC) 可以在適當大小的 SBC 上執行完整的 TensorFlow,但請注意,其功耗通常遠高於 MCU 或 DSP,通常會消耗 10 至 20 W。
一般而言,模型會在 TensorFlow 上完成訓練,若模型要在輕量型嵌入式系統上執行,就需要經過轉換,才能在 LiteRT 上執行。
PyTorch 和 ExecuTorch
 資料來源:
資料來源:為了滿足在本機硬體平台上執行機器學習模型不斷增加的需求,PyTorch 開發出 ExecuTorch。這是一套完整的端對端軟體工具,可在智慧型手機、穿戴式裝置和嵌入式平台上執行機器學習模型。ExecuTorch 能夠跟一般 PyTorch 一樣執行相同的工具鏈和 SDK,從建模、轉換到部署,也可相容於多種 CPU、NPU、DSP 平台。
ExecuTorch 使用 PyTorch 2.0 構建,因此更容易使用,並且支援眾多裝置,包括智慧型手機應用程式的 Android 支援。
PyTorch Edge、ExecuTorch、PyTorch Mobile 有什麼不同? 解答
PyTorch Edge 是在邊緣執行機器學習模型的概念。PyTorch Mobile 是達成這一切的傳統工具組,而 ExecuTorch 是在邊緣端執行 PyTorch 模型的現代工具組。
PyTorch Mobile 是早期為了將 PyTorch 轉移到行動裝置所開發的工具,特別適用於 iOS、Android、Linux 架構的行動裝置,但由於在應用初期就需要佔用靜態記憶體,因此較少採用。ExecuTorch 則採用動態記憶體,這代表只在需要時才會分配記憶體,這對於記憶體受限的環境而言是關鍵的步驟。
可以在 PyTorch 上執行我的 TensorFlow 模型嗎 (或是反之)? 解答
雖然 TensorFlow 和 PyTorch 是類似的軟體環境,但目前彼此之間無法直接相容。由於每個系統使用的訓練方法和模型檔案輸出有所不同,因此要在不同生態系統之間使用相同的模型並不容易。
幸好,有另一個方式可以輕鬆進行兩者之間的轉換。開放式神經網路交換器 (ONNX) 是一套開源的機器學習軟體系統,其中的工具可讓訓練模型檔案在不同的機器學習生態系統之間進行轉換。
ONNX 可當作不同機器學習生態系統之間的中介步驟,能讓開發人員使用多種不同的機器學習訓練方法,並針對各種方法進行模組最佳化。
熱門機器學習軟體內容

Syntiant TinyML 微型機器學習使用什麼軟體
Syntiant TinyML(微型機器學習, Tiny Machine Learning) 開發板是一個用於建立低功耗語音、聲音事件偵測 (AED) 和感測器 ML 應用的平台。




Renesas 的 Reality AI Tools® 技術問答
Renesas Reality AI Tools® 幫助工程師基於先進的訊號處理技術,來產生和構建 TinyML/Edge AI 模型。使用者可以自動探索感測器數據,並產生最佳化模型。
邊緣人工智慧和機器學習硬體
TensorFlow Lite for Microcontrollers 是一個機器學習軟體平台,專為微控制器規模的應用所設計。不需要作業系統,因此 C 或 C++ 函式庫或動態記憶體應用程式能讓 TensorFlow Lite for Microcontrollers 雖然精簡卻比標準程式設計選項更強大。
為何要在微控制器上使用邊緣人工智慧? 解答
微控制器微小、靈活、低功率且低成本的元件,安裝於全球數十億台裝置中。在不需要完整電腦系統的應用中,微控制器享有優勢。微控制器在機器學習領域中別具吸引力,因為能以本機方式對傳入的資料進行決策與處理。在本機處理資料還有另一項優點,就是可以保護最終使用者的隱私。舉例而言,您可能想知道是否有人接近您家中的大門,卻不必將門鈴攝影機的影像資料上傳到雲端。
需求
TensorFlow Lite for Microcontrollers 是以 C++17 程式設計語言開發,需要 32 位元微控制器平台才能運作。
TensorFlow for Microcontrollers 的軟體核心作業可以在 ARM Cortex M 平台上運作,最少僅需 16 KB 記憶體,此外也已移植到常用的 EPS32 平台上。若您偏好在合適的 Arduino 平台上使用,甚至還有推出 TensorFlow Lite for Microcontrollers 框架用的 Arduino 軟體庫。
TensorFlow Lite for Microcontrollers 有哪些限制? 解答
雖然 TensorFlow Lite for Microcontrollers 是強大的機器學習平台,且可在最低的硬體要求下運作,但仍有一些限制會造成開發困難:
- 官方僅針對少數裝置提供支援,通常是高效能的 32 位元平台
- 與 TensorFlow Lite 一樣,都不支援在微控制器上進行裝置訓練。
- 僅支援一小部分基本的 TensorFlow 作業。
- 若要進行記憶體管理,可能需具備低階 C++ 應用程式開發介面 (API)。
其他嵌入式系統
將機器學習模型部署在更強大的硬體系統,如可執行嵌入式 Linux 或 Raspberry Pi 平台的 SBC,也可執行 TensorFlow Lte 平台。
硬體加速器
在晶片層級,在特定處理器上添加更多專用的算術邏輯,以輔助使用的機器學習和神經網路進行運算。
NPU
神經處理單元 (NPU) 是專用型 IC,可加速基於神經網路的機器學習和人工智慧應用加快處理速度。
神經網路是基於人腦的結構,具有許多互連層和節點,稱為神經元,可用於處理和傳遞資訊。
TPU
張量處理單元 (TPU) 是 Google 於 2015 年開發的專用型 IC,輔助神經網路式系統的處理,與 NPU 不同之處在於,並非透過神經元式系統架構完成,而是利用快速處理矩陣乘法和卷積運算。
TPU 經過深度最佳化,能在低能耗下處理數學矩陣運算,因此非常適合用來訓練採用 TensorFlow 和 ExecuTorch 等運算的機器學習模型。
第一代 TPU 硬體通常只用於資料中心應用,因為有電源和散熱的需求。但最新一代的 TPU 則專為邊緣應用所設計。
為什麼 CPU 和 GPU 不常用於邊緣人工智慧? 解答
傳統的中央處理器 (CPU) 非常適合一般用途運算,但尚未經過最佳化,無法有效率執行神經網路的所有算術。圖形處理單元 (GPU) 對機器學習和人工智慧應用也變得非常實用,然而,龐大的能源開銷以及硬體需求,使其在邊緣的應用受限。
入門級產品



中階產品
![]()

STMicroelectronics STM32N6 採用運作頻率為 800 MHz 的 Arm® Cortex®-M55。Cortex-M55 是首款引進 Arm Helium 技術的 CPU。

![]()

Raspberry Pi 5 是架構在一顆 64 位元四核心 2.4 GHz Arm® Cortex®-A76 處理器之上,與 Pi 4 相比,CPU 效能可提高兩到三倍。
高階產品

![]()
具有神經網路加速器的超低功率 MAX78000 Arm® Cortex®-M4 處理器

Analog Devices 的 MAX78000 是新型的 AI 微控制器,旨在讓神經網路能夠以超低功率執行,並安置在 IoT 的邊緣。
![]()
32 位元 STM32 F7 系列 MCU 具有 ARM® Cortex™-M7 核心

STM32 F7 MCU 系列的操作頻率高達 200 MHz,並且使用 6 級超純量管線和浮點單元 (FPU),能產生高達 1000 CoreMark。
專業級產品


更多產品
熱門邊緣人工智慧硬體內容

DFRobot 的開源硬體如何降低 AI 創新的門檻?
在本系列的第一集,DFRobot 資深工程師 Rockets Xia(夏青) 將帶領我們探索: AI 如何重新塑造人類的感知方式? DFRobot 的硬體如何讓 AI 創新不再只是專家的專利?

與DFRobot共探AI 智超現在: EP4 擴展感知邊界:AI驅動環境監測革命性演進 #DFRobot #DigiKey
分享針對環境檢測的 AI 項目,包括資料獲取、邊緣推理與回饋機制設計。

與DFRobot共探AI 智超現在: EP2 從集中到分佈:TinyML和本地離線AI的關鍵作用 #DFRobot #DigiKey
剖析 TinyML 與離線 AI 推理在現代工業與消費場景中的優勢。


Edge Impulse
Edge Impulse 是基於雲端的整合式開發環境 (IDE),能讓軟體開發人員收集和匯入真實世界的資料,並且構建、訓練、測試機器學習模型,以達到在邊緣運算裝置上有效率執行。
 Edge Impulse 和 TensorFlow 機器學習軟體的差異在於,Edge Impulse 將模型開發過程對使用者進行抽象化處理,而 TensorFlow 的開發過程則複雜得多。
Edge Impulse 和 TensorFlow 機器學習軟體的差異在於,Edge Impulse 將模型開發過程對使用者進行抽象化處理,而 TensorFlow 的開發過程則複雜得多。
Edge Impulse 的優勢
Edge Impulse 框架可以搭配音訊 (麥克風) 到影像 (相機),再到感測器資料 (振動感測器) 的所有內容運作。其他範例包括:
- 物體識別和影像偵測 (如偵測人員等)
- 透過音訊偵測「喚醒詞」(用於智慧家庭助理)
- 異常偵測 (用於預防性維護)
- 活動/模式識別 (用於簡化流程)
使用 Edge Impulse 的優點為何? 解答
Edge Impulse 可以減輕機器學習訓練軟體 (目前主要是 TensorFlow) 需要完成的工作負擔量。Edge Impulse 提供 Web 介面,可在其中標記和上傳訓練模型的資料。
Edge Impulse 專為從未接觸過機器學習訓練軟體的使用者或非機器學習領域的開發人員所設計,但因為相容於 TensorFlow Python 框架,因此也可完整擴充,滿足專業使用者的需求。因為除去建立邊緣人工智慧模型時大多數的程式碼阻礙,能讓人員更專注於提供正確的資料、訓練正確的模型,而不用操心要執行程式碼所要涵蓋的 Python 函式庫。
雖然大多數開發人員和使用者都享有免費使用權限,但會在專案數量以及各專案可運用的處理能力有所限制。專業開發人員可聯繫 Edge Impulse 團隊取得報價,享受更多功能。
熱門 Edge Impulse 內容





熱門的 Edge Impulse 裝置
![]()

Nordic Semiconductor 的 Nordic Thingy:53 利用整合式的動作、聲音、光線、環境感測器來協助打造概念驗證和原型。

相容的 Edge Impulse 開發板完整清單:Edge Impulse Edge 人工智慧硬體概覽
利用人工智慧進行感測
儘管執行機器學習模型需要嵌入式系統,未來還是會推出更多具備人工智慧能力的電子元件產品。包括人工智慧功能感測器,或稱機器學習感測器。
機器學習感測器的用途
雖然在大多數感測器中添加機器學習模型,並不會提升其應用執行效率,但有些類型的感測器,可透過機器學習訓練大幅提升其運作效率。
- 在相機感測器中開發機器學習模型,就可追蹤畫格中的物體和人員。
- IMU、加速計、動作感測器可用於偵測活動曲線。
具有機器學習功能的視覺感測器
透過神經網路提供運算演算法,就可在物體和人員進入相機感測器的視野時進行偵測和追蹤。
熱門的人工智慧視覺感測器

![]()
用於 STM32 板的 B-CAMS-OMV 攝影機模組同捆套件

STMicroelectronics 的 B-CAMS-OMV 攝影機模組同捆套件內含 5 MP 攝影機模組和一塊具有擴充連接器的轉接板。

熱門人工智慧視覺感測器內容

具有機器學習功能的動作感測器
具有整合式機器學習平台的動作感測器,能在與感測器共用的封裝中即時追蹤和處理資料,進而降低功耗和處理時間。這類型感測器絕大多數都有小型的運算邏輯架構決策樹,或具備預先定義濾波器或觸發域值的能力。當輸入值達到此位準時,就會執行動作。其他動作感測器在封裝中內建完整的 DSP 單元,因此無需主 CPU 就可執行多重機器學習演算法,進而節省電力和時間。
熱門的人工智慧動作感測器


熱門動作感測器內容

解碼:可高效開發AI環境感測系統的感測器與開發板套件
但現在,一套由 AI 和感測器組成的 「超感官系統」 正在幫我們撬開這些隱藏的環境真相。 今天,「AI共行,智超現在」系列第4集,夏青(Rockets Xia)老師會帶著大家利用DFRobot的硬核工具,把看不見的環境變化,變成能看懂、能預警、能互動的 “生活指南”。

善用開發板和模組 實現多模態感知AI
今天,「AI共行,智超現在」系列第三集,DFRobot的夏青(Rockets Xia)老師會帶著大家一同瞭解:AI 是如何突破單一功能限制,像人類一樣 “能聽、會說、能看”的。 同時,DFRobot 的開源硬體又是如何讓普通人也能玩轉這些黑科技。

具有機器學習功能的環境感測器
整合機器學習平台的環境感測器能夠即時處理資料,且本身也具備機器學習處理能力。此類感測器大多會偵測環境值的變化,例如溫度快速上升,這可能表示冷卻器已離線。


