

How the RISC-V Atomic Extension Gives You Superior Bit Manipulation Capabilities
The rate of RISC-V architecture adoption is quickly snowballing, and for good reason, its influence in the industry is increasing.
Besides the core architecture and its true reduced instruction set architecture (ISA), it is enhanced by a series of standardized extensions (Figure 1). For example, a 32-bit RISC-V core (RV32) that supports single-precision floating-point and also compressed instructions would be designated RV32FC, per the extension list shown.
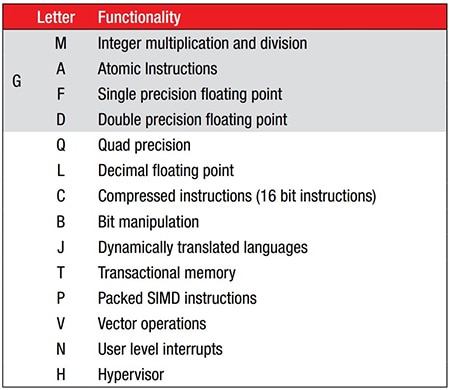 Figure 1: The RISC-V ISA is enhanced by a series of standardized instruction extensions, denoted by a letter suffix after the core name. (Image source: RISC-V.org)
Figure 1: The RISC-V ISA is enhanced by a series of standardized instruction extensions, denoted by a letter suffix after the core name. (Image source: RISC-V.org)
For many artificial intelligence (AI) and machine learning (ML) applications, as well as advanced embedded systems, the four most necessary extensions are integer multiplication and division (M), atomic instructions (A), single-precision floating-point (F), and double-precision floating-point (D). However, instead of designating a core as RV32MAFD, these are all grouped together under the G suffix, as in RV32G.
For more on the various extensions and RISC-V in general, see DigiKey’s RISC-V ebook found on the EDU site.
For myself, since my initial experience with processors was in deep embedded systems, I tend to look closely at an architecture’s read-modify-write bit manipulation support on data memory. For these applications, setting and clearing bits for peripheral registers and semaphores are very common. Without native bit manipulation instructions, a core would need to copy the contents of the data memory locations to a core register, set, clear, or toggle the bit(s) using OR, AND, or XOR instructions, respectively, and then store the result back into the data memory location. This not only takes additional time, but in some cases, I’ve seen code bloat as high as 20% for some embedded control applications.
For some applications, the code bloat and decrease in performance can be acceptable. However, while these three instructions are being processed, an interrupt can rudely remove program control from the operation, or even worse, in a multi-processor system, another core might read from that same memory location. Disabling interrupts or locking memory to ensure these events do not corrupt data memory requires additional instructions and complications that can generate performance problems.
Arm attempted to solve these problems by implementing bit-banding, which works for simple bit operations. However, in my opinion, RISC-V has implemented a more elegant and flexible solution.
Why the Atomic extension is so elegant
The RISC-V A (Atomic) extension supports two operations, a Load-Reserved/Store-Conditional instruction, which won’t be discussed here, and a binary/bitwise instruction which provides for simple bit manipulation on data memory. While the RISC-V B bit manipulation extension supports a series of complex bit control instructions, the Atomic extension is not just targeted towards multiprocessor systems. It also helps in smaller embedded systems where the necessary bit manipulation needs are simpler. An example of such a system is Seeed Technology’s 114991684 dual-core, 64-bit, RISC-V module. It has two RV64GC cores that need to work together and play nice with their shared data SRAM.
The format of the RISC-V A-extension atomic memory operation (AMO) is shown in Figure 2.
 Figure 2: The RISC-V AMO instruction format supports atomic binary operations on data memory with just one instruction. (Image source: RISC-V.org (enhanced by Bill Giovino))
Figure 2: The RISC-V AMO instruction format supports atomic binary operations on data memory with just one instruction. (Image source: RISC-V.org (enhanced by Bill Giovino))
The AMO is a powerful read-modify-write instruction that supports various binary operations directly on the data memory pointed to in rs1 with just one instruction. Referring to Figure 2, the operation loads the contents of the data memory address location in rs1 and stores the value in register rd. It then performs a binary operation on the value of rd with the value in rs2, and stores that result back in rd and back into the data memory address location in rs1.
Bitwise operations supported are OR (bit set), AND (bit clear), and XOR (bit toggle). This allows atomic bit manipulation of one or more bits directly on data memory. This also prevents memory conflicts when the two RV64GC cores are using the same memory address at the same time. This is extremely useful for small embedded applications when configuring peripheral registers in memory, as well as simplifying semaphore operations.
Additional operations supported by the RISC-V AMO are integer maximum, integer minimum, and swap. Binary ADD is also supported which allows direct binary addition, including directly incrementing a counter in data memory.
The RV64 core supports both 32-bit and 64-bit operations. For bit manipulation with the RV64, it is important that it only operates on 64-bit data, as the operation will sign-extend 32-bit data placed in rd.
Conclusion
The RISC-V ISA is the first serious contender to come and challenge the Arm ISA. Its ISA extensions provide a standardized method of enhancing the core with instructions that can cost-effectively improve performance for an application. I’m particularly excited about the optional Atomic extension.
While useful and almost necessary for multiprocessor systems, the Atomic extension is also an efficient way of providing bit manipulation control directly on data memory. This provides a significant advantage over many existing architectures by reducing code size and improving performance.
About this author

Bill Giovino is an Electronics Engineer with a BSEE from Syracuse University, and is one of the few people to successfully jump from design engineer, to field applications engineer, to technology marketing.
For over 25 years Bill has enjoyed promoting new technologies in front of technical and non-technical audiences alike for many companies including STMicroelectronics, Intel, and Maxim Integrated. While at STMicroelectronics, Bill helped spearhead the company’s early successes in the microcontroller industry. At Infineon Bill orchestrated the company’s first microcontroller design wins in U.S. automotive. As a marketing consultant for his company CPU Technologies, Bill has helped many companies turn underperforming products into success stories.
Bill was an early adopter of the Internet of Things, including putting the first full TCP/IP stack on a microcontroller. Bill is devoted to the message of “Sales Through Education” and the increasing importance of clear, well written communications in promoting products online. He is moderator of the popular LinkedIn Semiconductor Sales & Marketing Group and speaks B2E fluently.

Have questions or comments? Continue the conversation on TechForum, DigiKey's online community and technical resource.
Visit TechForum




